Whoops, I built a data replication engine (2/3).
In the first installment of this post, I talked about how I came to the depressing realisation that I might need to go out on the bleeding edge to build a sync service for a simple shopping list app. In this part I’ll go into what I did about it.
Symmetry
The core of the problem is that, in an asynchronous, delta-based sync protocol, both the client and server need to track the other’s state in order to be able to compute the smallest delta needed to bring each other up to date.
Framing the problem this way put me in mind of a distributed data replication system that I was already using every day: git. Maybe I could just build on that?
I could certainly store a JSON-like blob of text in git, have a branch per client device, and trigger the equivalent of a git pull from the devices when a blob changes. git would handle merging any divergent data, generating and applying diffs. So, yay?
Of course, there were a number of catches:
I’d need lots of hooks into git, any of which could prove problematic. At the very least I’d need to integrate my own conflict-resolution logic.
I’d need to embed parts of git into the app, and the git source is GPLv2-licensed, making it very tricky, verging on impossible to embed in an App Store app.
- In this application there will be many tiny little changes (add this item, check that item, move this item to that location, etc). The majority of these changes will never even be seen by other clients: they’ll be folded into a consolidated update when they next come online.
Now, git is (in)famous for allowing users to rewrite history, so some variant of
git rebaseorgit merge --squashmight be used to prune commits to a reasonable number. But this is certainly not how git is meant to be used.
Git-Flavoured Replication
So I decided against actually using git, but to use the same model: a graph — specifically, a directed acyclic graph — of states representing the history of changes, using a hash of the data in each state as its ID, with the edges between states holding deltas.1
Here’s an example:
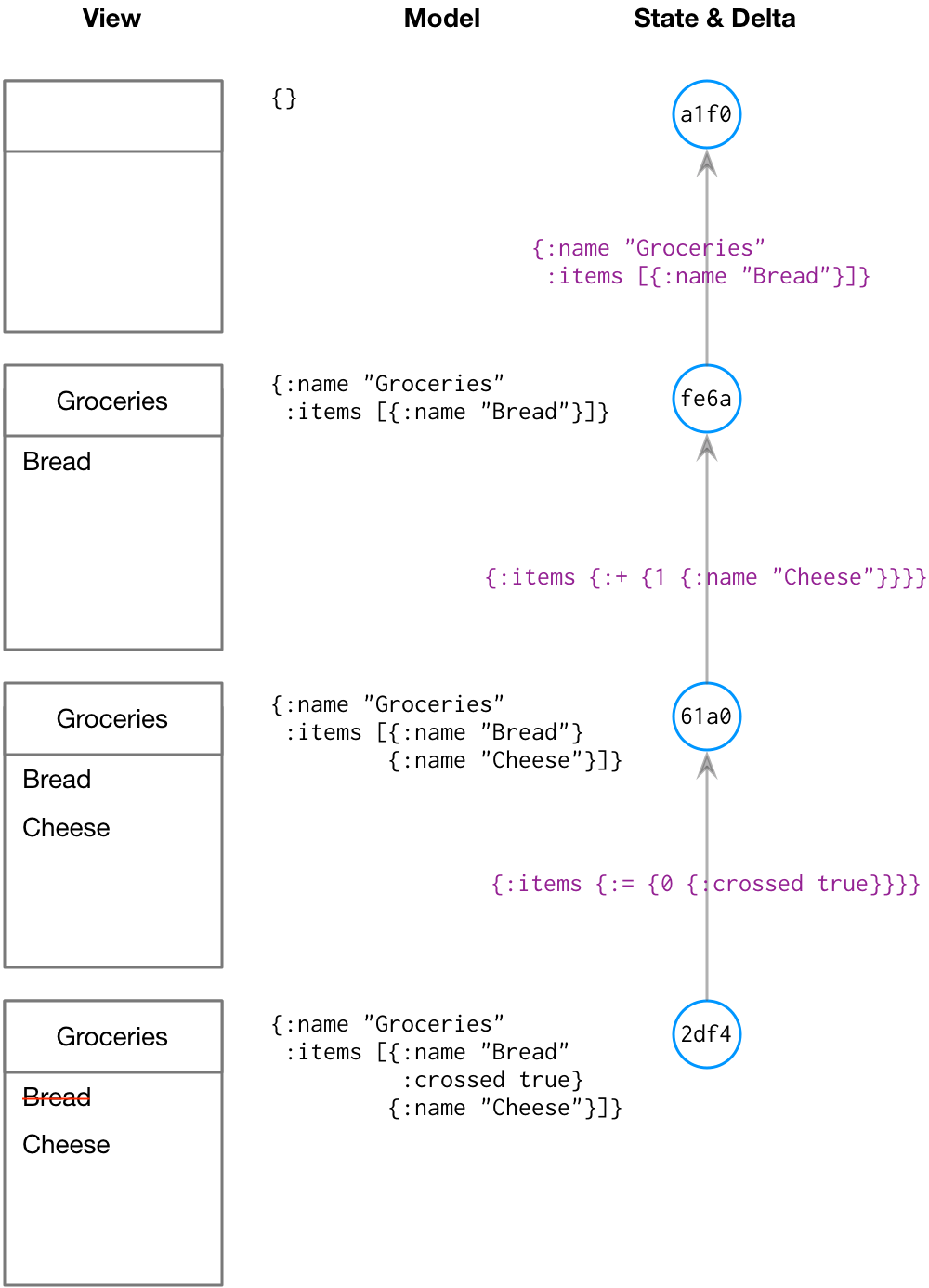
The rows from top to bottom are a sequence of states in a shopping list. For any given row, the three columns show the states’:
View. What the user sees.
Model. The data underlying the view. The data is shown in EDN, which has similar usage and form to JSON: like JSON it supports maps (aka hashes/dictionary’s), lists, strings, numbers, as well as keywords which start with ‘:’ and can be thought of as unique strings.
State & delta. Each state is a graph node, labeled with its ID, with an edge to the node it derives from, labeled with the delta describing the change in data. Note that the arrows indicate the ‘is a parent of’ relation, not the direction of time (which runs the opposite way).
A state’s ID is, like git, calculated from a hash of the state’s data (plus the ID’s of its parents).
Deltas are themselves EDN data. A delta against a map is simply the updated name-value pairs. For example, the fe6a state in the second row changes the root state (an empty map) to one representing a shopping list named ‘Groceries’ containing a single item, ‘Bread’.
A delta against a list uses special map keys representing add (:+), update (:=), and delete (:-) operations. So {:items {:+ {1 item}}} means ‘insert item at position 1 in items’, {:items {:= {1 delta}}} means ‘apply delta to item 1 in items’.2
These sequences of many little deltas are typical: clients send changes in real-time, so there will often be many states with small deltas added in a session. We obviously need to manage this somehow to prevent the state sequences growing forever, and the answer is …
Garbage Collection
To support GC, the system tracks the last state known to be on each client (the equivalent of a ref in git). After each change, the system updates the heads, and runs a GC pass.
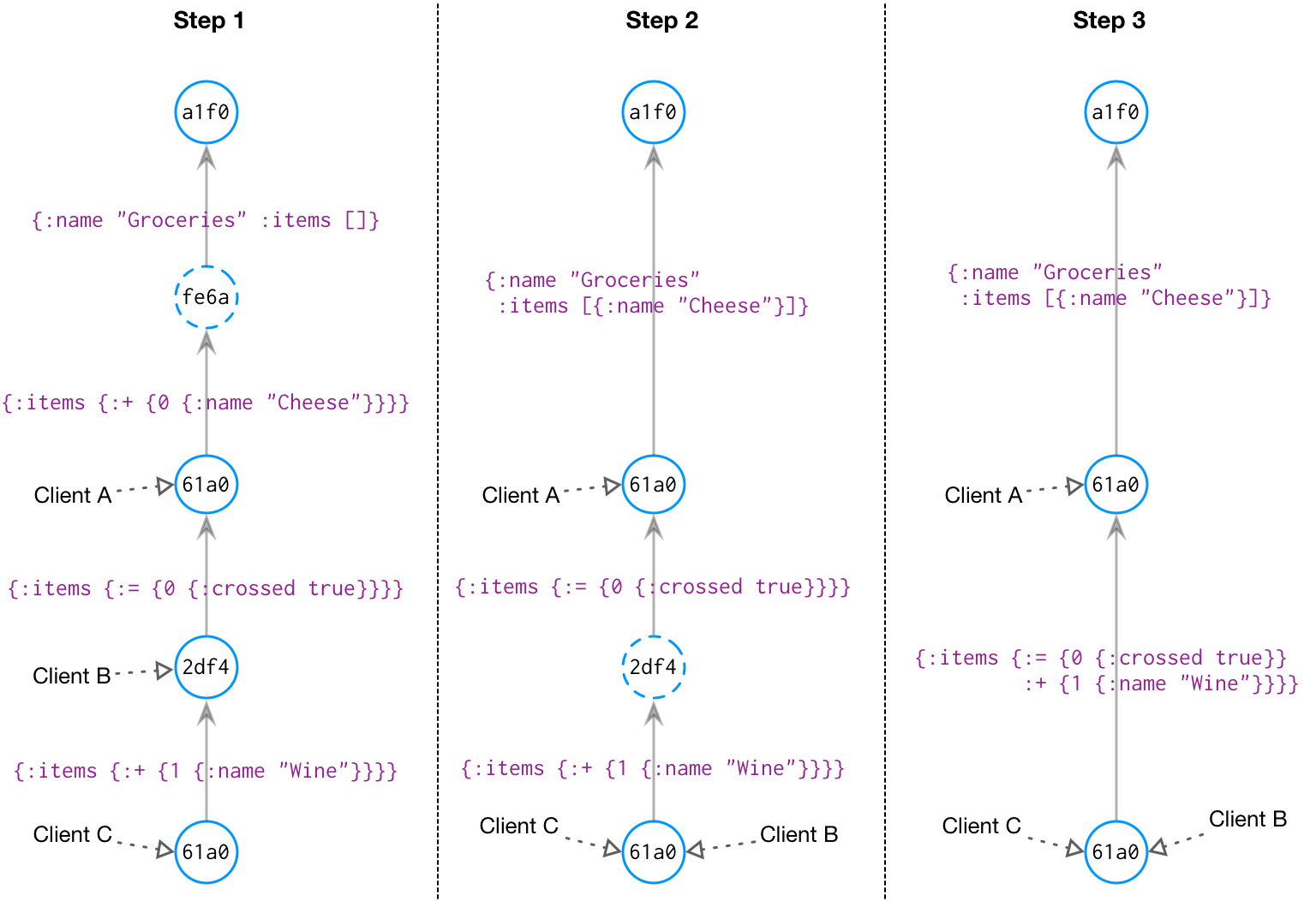
The columns in the diagram above shows three iterations of a graph model. In Step 1, the last three states are marked as referenced by clients: these are the states last known to be on these devices. The next time these clients request an update, these states define the deltas we’ll send to bring them up to date; the unreferenced states can be folded into their parent.
To bring Client B up to date, we would simply send the delta between the head state and its parent:
{:items {:+ {1 {:name "Wine"}}}}
Client A would get the last two deltas folded into one:
{:items {:= {0 {:crossed true}}
:+ {1 {:name "Wine"}}}}
In Step 1, state fe6a is not referenced, so it has been GC’d in Step 2. Client B has also been updated to the head state, and we can drop state 2df4, shown in Step 3.
Missed Messages
So, we now have a way to track what changes need to be sent to what clients, and keep the number of states we need to track down to a minimum. But what about when an update message gets lost?
For example, what if the update we sent to Client B in Step 2 was dropped due to the client losing its cell signal unexpectedly? The server has dropped the 2df4 state, so the next time Client B sends a delta update it’s going to be from a non-existent parent from the server’s point of view.3
In this case, the answer is simple:
We let the client know that we don’t have that state.
The client responds by sending a full delta against the empty root (
a1f0) state, which is always valid.
We cop a penalty in bandwidth, but we can see that two important results are illustrated:
Regardless of how it happened, the hash-based state ID scheme ensures the client and server will eventually discover if they’re out of sync.
The client always has a fall-back to get back in sync: just send everything and let the server figure it out.
This turns out to be a very nice property to have, and in practice it’s made the sync service very tolerant of random errors.4
In the next part I’ll talk about handling the case where the client and server become out of sync for a different reason: when their states diverge.
Unlike my system, git actually stores whole files in a compressed format, not the actual diffs that were checked in. ↩︎
The JSON patch format is a similar way of describing deltas for JSON objects. The delta format described here is equivalent, but tends to be more compact since it merges all changes into a single map, rather than a series of patch operations. ↩︎
The server could be less aggressive with its GC to reduce the likelihood of this happening. In fact my original design kept both the last state known to be on the client, and the state we just sent it. But this turned out to add a lot of complexity for little gain. If the penalty for missing states were higher, then GC could be tuned to keep them for longer. ↩︎
It’s not as tolerant of programmer bugs unfortunately, especially if the bug is that the client and server disagree on the state’s hash ID… But I’ll leave that story for another time. ↩︎